Developer Experience
Real-world scenario
Picture the scene: you are working with a very talented developer, who can churn out a really astounding amount of code every day. However - they never reuse code, instead preferring to copy + paste the same code into multiple places literally 5-6 times. If that code snippet ever needs updating, it's a find + replace job with no guarantees you'll find every usage. Tests are nowhere in sight, relying instead on the diligence of the developer. Because no code is re-used, every API endpoint is independent and any code changes require re-validating manually via the API / GUI.
This is exactly the position I found myself in in a previous role. There was no doubting this developer's attention to detail and ability to spot bugs before they happened, but by not following standard practices, the codebase was incredibly bloated and every single new endpoint / new feature had to be written from scratch. It proved to be a very slow and fragile way of working, in my opinion.
So I began packaging common functionality into classes. A simple retry manager for requests to external systems, a standard way to name inputs to get automatic filtering on querysets, etc. We were doing input validation on large JSON payloads, so I developed a validation framework that was recursive so we could define the allowable structure, and just write validator.validate(payload). This framework auto-generated documentation for our API as well, and this documentation was automatically kept up-to-date as we made changes to the validation rules (unlike the old approach, which contained a lot of stale documentation).
The day it all changed
One day, both the other dev and I were assigned very similar tasks - a LIST endpoint each for two of our database models. The other dev spent a full day writing ~200 lines of code, while I spent ~2 hours writing ~35 lines of code. I realised that I had become much more effective than the original developer, despite the fact that I knew he was a faster worker than me.
This was an eye-opener for me at the time. But with hindsight, it was not surprising. His refusal to improve his toolset was ultimately slowing him down - or, more accurately, preventing him from speeding up.
Illustration of the problem
Using some fairly loose numbers, let's assume that:
- The original developer was x2 as productive as me when I started.
- Every week, I made small improvements that made me 5% more productive.
- My productivity improvements compound.
- My starting output is 1 "unit" per week, while the other dev's output is 2 "units" per week.
In this simplistic, idealised scenario, here is how our output looked after 16 weeks:
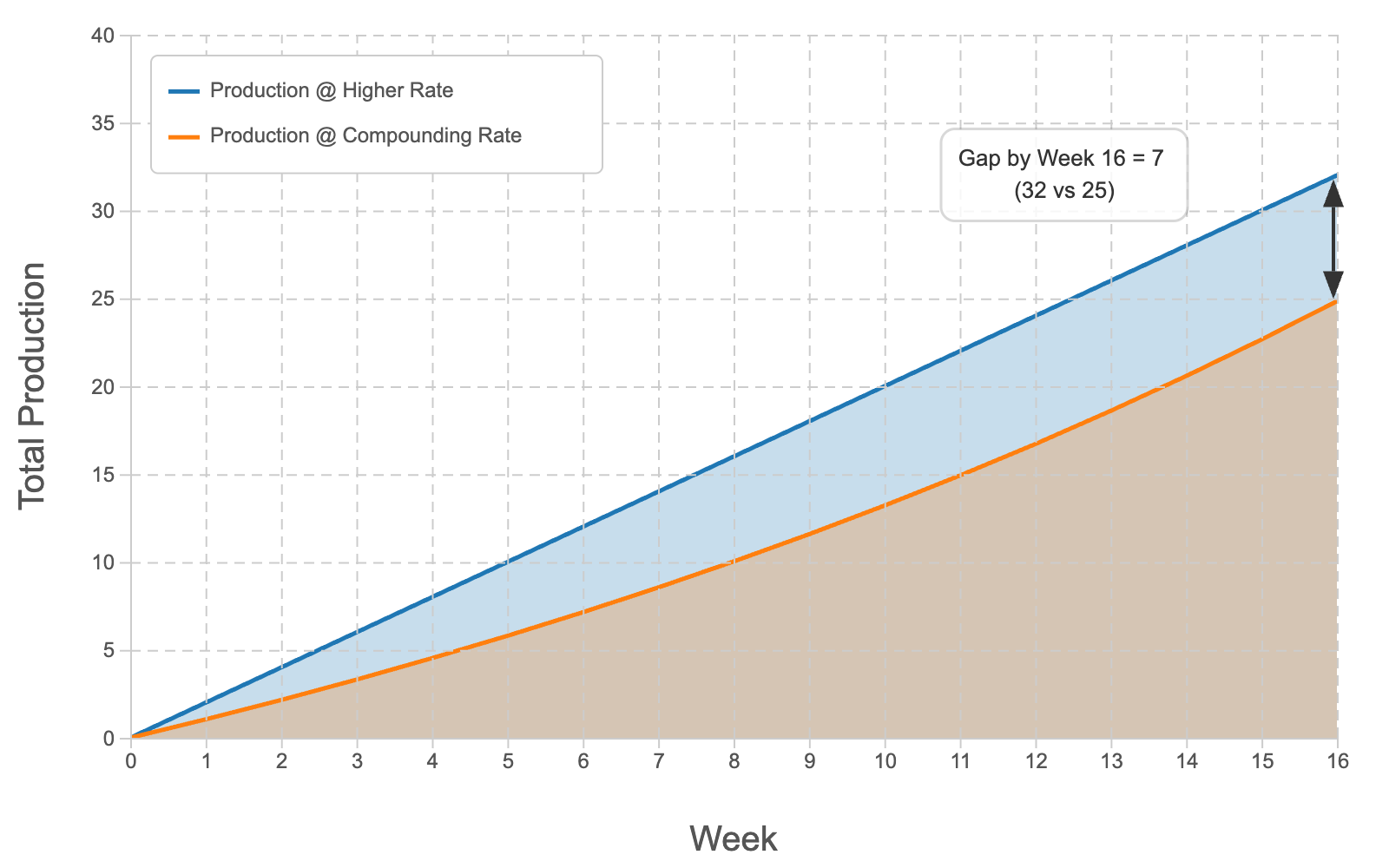
I was clearly behind, and falling further behind every week.
But by week 32, this is how our output looked:
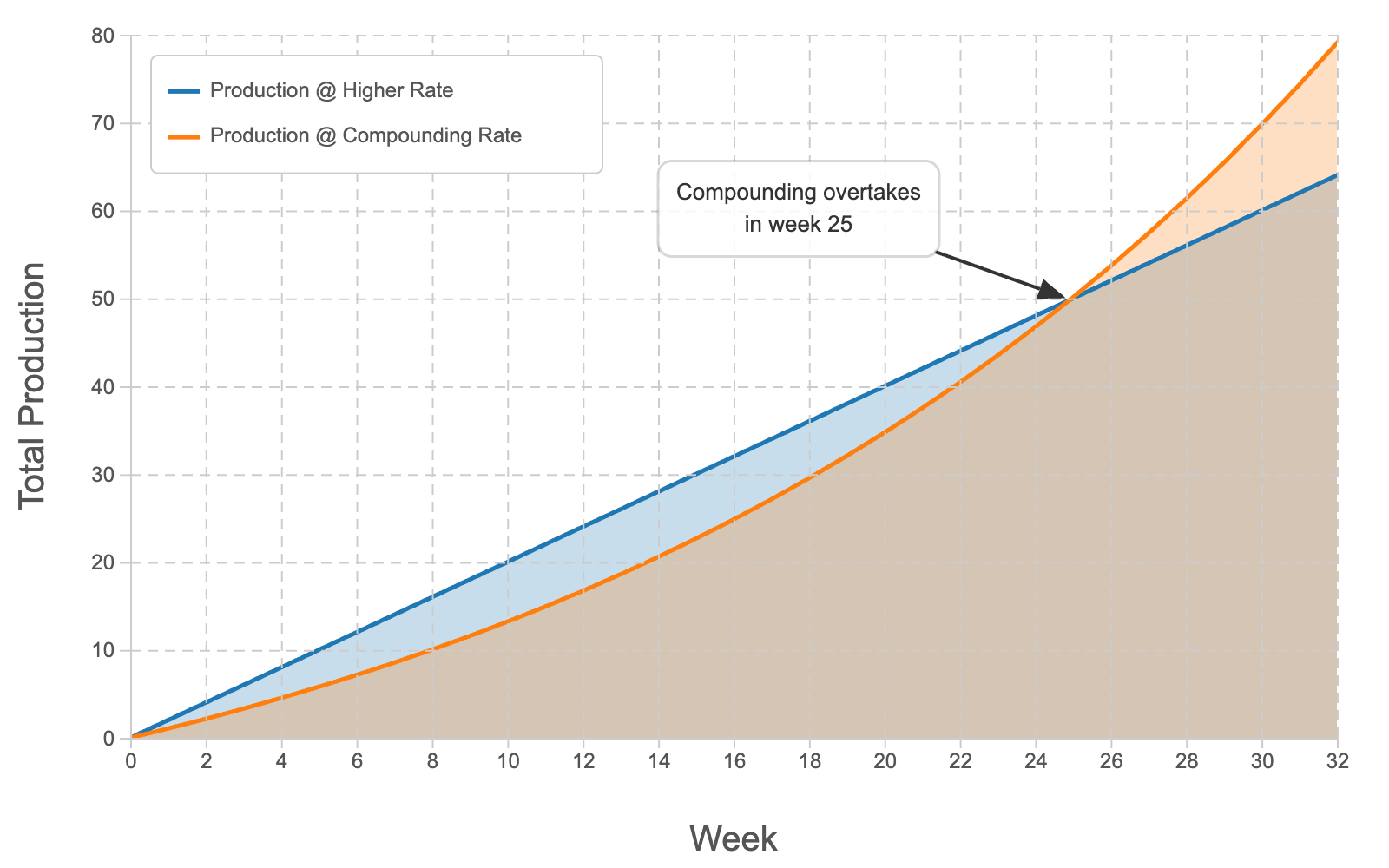
I had actually overtaken his productivity around week 25 by making small, continuous improvements.
And playing this scenario out to the end of the year, this is how our output looked:
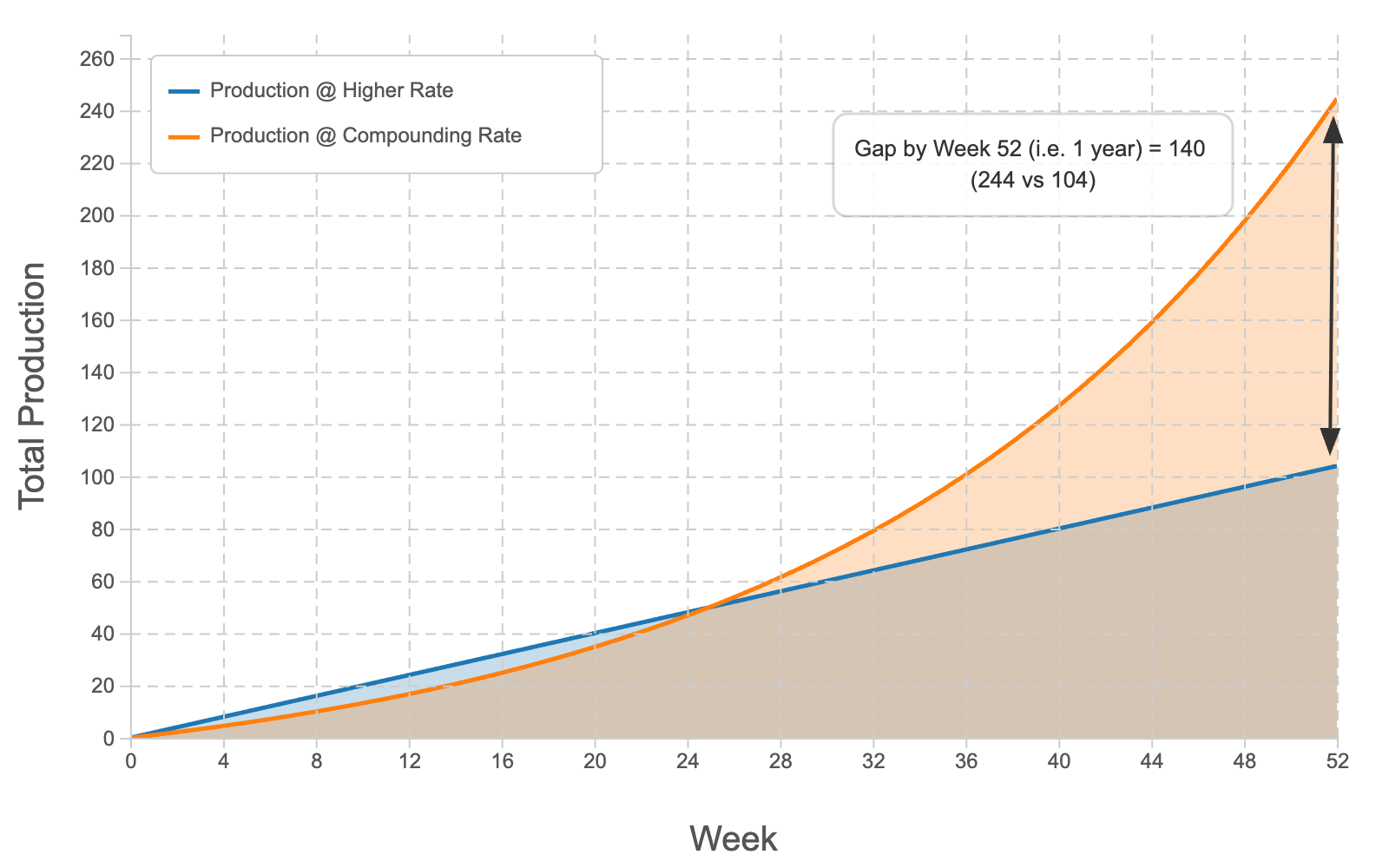
By the end of the year, I had actually produced more than twice as much as he had. From starting out at half his productivity, by the end of the year I was producing twice as much as the other dev - a 4x increase on my own productivity since the beginning of the year.
Obviously, this is an idealised scenario and productivity is hard to measure and certainly is not as simple as these charts convey. But the point remains - small, continuous improvements compound and lead to massive productivity improvements.
Conclusion
Every hour spent on creating reusable code can save x10 hours in the future. It's an investment that pays off in the long run, though management often don't see it that way. I totally understand that deadlines must be met and sometimes, you just need to get the work done and out the door, but this is a short-term view that can lead to long-term problems.
In my current role, we have numerous mixins that allow us to test hundreds of input scenarios with absolutely minimal code / data configuration. This helps us develop a robust API very quickly and effectively. I have also re-built that validation framework and improved it in many ways - it now underpins our GraphQL schema and performs automatic validation of all inputs, and provides consistent and well-documented error messages to our users.
The effect on our productivity has been, and continues to be, huge. I would highly recommend this approach to anybody working in technology.